Internet of Things lecture material 
Here is a compilation of notes and potential lecture materials around various topics I have condensed in the past few months.
The notes are written in markdown and generated using mdBook. The contents are MIT Licensed and so is any code they might contain. You can find the source code on GitHub.
Please report issues and feature requests on the GitHub issue tracker.
The Internet Engineering Task Force (IETF)
In 1998 the Internet had about 50 million users, supported by approximately 25 million servers (Web and e-mail hosting sites, for example, but not desktops or laptops). Today the estimation is that some 3.4 billion people are regular users of the Internet, and there are some 20 billion devices connected to it. We have achieved this using some 3 billion unique IPv4 addresses. Looking ahead, there are estimations of several other billions of devices to be soon connected to this network. Noone thought that this feat could be achievable and yet it has happened with almost no fanfare.
A large portion of this success has been done by the work of engineers at organizations that are more or less unknown to the public. Being the Internet Engineering Task Force (IETF) the most prominent.
What has the IETF done for us anyways?
IETF's mission is to make the Internet work better, and it tries to do so by creating high quality, relevant technical documents that influence the way people design, use, and manage the Internet. Those formal documents have behind them consensus and several implementations before they are assigned the usual Request for Comments (RFC) number. Many of those RFCs have already been implemented and run on every connected machine today:
- RFC791 The Internet Protocol.
- RFC792 The Internet Control Message Protocol.
- RFC821 The Simple Mail Transfer Protocol.
- RFC768 User Datagram Protocol.
- RFC959 The File Transfer Protocol.
- RFC793 The Transmission Control Protocol.
- RFC854 Telnet Specification.
- RFC1119 Network Time Protocol.
- RFC1157 A Simple Network Management Protocol.
- RFC1035 Domain names - implementation and specification.
- RFC1945 Hypertext Transfer Protocol.
- RFC1964 The Kerberos Version 5 GSS-API Mechanism.
- RFC2131 Dynamic Host Configuration Protocol.
- RFC2246 The TLS Protocol Version.
- RFC2328 The Open Shortest Path First routing protocol.
- RFC3261 The Session Initiation Protocol.
- RFC6455 The WebSocket Protocol.
- RFC5321 Simple Mail Transfer Protocol.
- RFC7540 Hypertext Transfer Protocol Version 2.
- RFC6749 The OAuth 2.0 Authorization Framework.
- RFC4271 The Border Gateway Protocol.
- RFC4287 The Atom Syndication Format.
- RFC4251 The Secure Shell (SSH) Protocol Architecture.
- RFC8200 Internet Protocol, Version 6 (IPv6) Sepcification.
While most RFCs are just proposals, miscellaneous protocol descriptions, or opinion/information documents, there are true Internet Standards among the RFCs and are maintained by the RFC Editor.
For the reader's pleasure I also copied two fantastic summaries of the changes that have happened to the Internet in a couple of decades:
You can also explore the RFC universe courtesy of Peter Krantz.
IETF Organization
As explained at the IETF website, the technical work of the IETF is done in its working groups, which are organized by topic into several areas (e.g., routing, transport, security, etc.). The IETF working groups are grouped into areas, and managed by Area Directors, or ADs. The ADs are members of the Internet Engineering Steering Group (IESG).
Much of the work in the IETF is handled via mailing lists. The IETF holds meetings three times per year. IETF Hackathons encourage collaboration on developing utilities, ideas, sample code, and solutions that show practical implementations of IETF standards. More recently GitHub has become a prevalent way to track the work and interact with developers more smoothly; for example CoRE, HTTP or TEEP use it regularly.
The Internet Architecture Board, (IAB) is responsible for defining the overall architecture of the Internet, providing guidance and broad direction to the IETF. The IAB also serves as the technology advisory group to the Internet Society ISOC).
There are very detailed guideline documents like RFC2418 that explain how WGs are created and what the roles of each individual are, but at a high level the IETF relies on "rough consensus and running code".
A draft's lifetime
It all starts with an author of set of authors that want to propose some solution for a specific problem they are facing. Usually the problem requires some interoperability and thus an Internet draft seems like the right approach.
-
An Internet draft is first publish as an individual submission by one or more authors. Literally anyone can write a draft and the requirements on that submission are very low.
-
Once the submission gets the attention of the Working Group, by discussing it on the mailing list, presenting it, doing implementations or evaluation... then the group can adopt it by doing a Working Group Adoption (WGA) call. Once agreed the document becomes a working group internet draft.
-
The draft will then go through many iterations and revisions, interop events, discussions, errata, and so on before the group thinks it is ready for Working Group Last Call which is the moment in which the group decides that the document is ready for publication.
-
After that the document is sent to the Internet Engineering Steering Group (IESG) for final review, IANA will due its due process and other and other editing will be done by/with the RFC Editor. After some time the document gets assigned an RFC number and is published.
-
After several years, providing there is industry adoption and the document is on the Standards Track i.e., it is not informational, the document may be come an Internet Standard. This whole process takes a long time and it can feel a bit slow, but at least the out put has guarantees of some consensus and some running code.
Contributing to IETF
The IETF is built by volunteers, if you are interested to take part, the best thing you can do is to start by reading the Tao of the IETF.
You then select a Working Group that fits your research/development interests and try to see which is the state of the art there. Most groups have a charter document that explains the why the group exists and what the purpose for the group is. In that same page you will have links to the many communication tools you can use.
-
Mailing lists are the primary form of communication, they usually start with the group name and then
@ietf.org, like core@ietf.org. -
jabber rooms work in a similar fashion core@jabber.ietf.org. However XMPP is used less and less these days.
-
Some groups have interim meetings which are online videoconferencing calls. Those are published on the mailing list.
-
Although the IETF doe snot run their own GitLab servers, Github is nevertheless used for collaboration and for tracking issues raised by the group and the authors. One example is http://core-wg.github.io
-
Finally, the best and most effective way of collaborating have been the face to face meetings happening three times a year. They can also be joined online.
The Constrained Application Protocol (CoAP)
The Constrained Application Protocol (CoAP) is a protocol intended to be used in low-powered devices and networks. That is networks of very low throughput and devices that run on battery. Such devices often have limited memory and CPU too, being the class 1 devices of 100KB of Flash and 10KB of RAM but targetting environments with a minimum of 1.5kB of RAM and about 5 kB of ROM.
CoAP is a REST-based protocol largely inspired by HTTP. However it brings the Web Server concept to the very constrained space where IoT devices are the ones exposing their resources.
Like HTTP, CoAP also uses request/response communication, being CoAP messages very small, of tens of bytes on a 6LoWPAN network and of the hundreds of bytes on a less constrained one.
CoAP devices are intended to come from multiple manufacturers, much like the World Wide Web enabled anyone to have an HTTP server. While arriving to a common data modeling and representation form as HTML for HTTP has not yet happened for CoAP, the technology is already mature in terms of networking layout.
Devices may be sensors and actuators, exposing resources (i.e., measurable data) or enabling interaction with the environment. They have to find ways to register to services, find each other, and interact without much human control or intervention.
Ideally we would be talking about a decentralized scenario, as on the Web. However, much like the Web is moving back to the mainframe format, most commercial IoT solutions today feature a central control point, manager, broker or orchestrating entity.
A CoAP Message
As specified on RFC7252, CoAP messages are very compact and by default transported over UDP. There is TCP support too (e.g., for NATed environments), but UDP is the intended original transport. CoAP messages are encoded in a simple binary format with a very compact header of 4 bytes. The version field indicates the CoAP version; the message type can be [ CON, NON, ACK and RST ]. This is followed by a method or response code [ 0.00 (Empty) , 0.01 (GET) , 0.02 (POST) , 2.05 (Success) , 4.04 (Not Found) ] and a message ID, which is a 16 bit field to detect message duplication. After the header, there is a variable-length token, which can be between 0 and 8 bytes long and is used to correlate requests and responses. Then there several options that allow for extensibility and finally the payload with the actual data. The 11111111 (255 in binary) is a marker to indicate the end of the options and beginning of the payload.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Ver| T | TKL | Code | Message ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Token (if any, TKL bytes) ...
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options (if any) ...
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|1 1 1 1 1 1 1 1| Payload (if any) ...
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Unreliable Transmission
As mentioned before, CoAP was intended for UDP transmission, which is unreliable. This means that CoAP request and response messages may arrive out of order, appear duplicated, or go missing without notice. For this reason, CoAP implements a lightweight reliability mechanism using four different message types, including "confirmable" and "non-confirmable" messages. If the messages is confirmable (CON), that means that either the request or the response require an acknowledgement (ACK).
To ensure retransmission in case of loss, the CoAP endpoint sending the CON message keeps track of a timeout for the message and a retransmission counter to keep track of how many times the message was sent.
The figure below shows how a simple CoAP Request would look like. The CoAP Client sends a confirmable request GET /temperature that requires an acknowledgment message from the server. The message ID is 0x7d36, which will be returned in the acknowledgment. Without the message ID, a client that makes two confirmable requests and gets two acknowledgements won’t know which acknowledgement goes with which request. A single CoAP request also triggers one or more responses, and the same token is used in every response. In the figure, the first message gets lost due to the unreliable nature of UDP, so the client needs to retransmit the message after waiting for an acknowledgement until some timeout.
Client Server (hosting a resource at "/temperature" with
| | value 22.3 degrees centigrade)
| |
+----X | Header: GET (T=CON, Code=0.01, MID=0x7d36)
| GET | Token: 0x31
| | Uri-Path: "temperature"
TIMEOUT |
| |
+----->| Header: GET (T=CON, Code=0.01, MID=0x7d36)
| GET | Token: 0x31
| | Uri-Path: "temperature"
| |
| |
|<-----+ Header: 2.05 Content (T=ACK, Code=2.05, MID=0x7d36)
| 2.05 | Token: 0x31
| | Content-Format: text/plain;charset=utf-8
| | Payload: "22.3 C"
The Content-Format option in the response explains the format of the content. This CoAP option will be further explained in CoAP Web Linking and Serialization.
Observing Resources
So far we have seen how CoAP can be used to access resources on a sensor running a tiny server. However, basic CoAP requires the client interested in the state of a resource to initiate a request to the server every time in order to get the latest representation. If a client wants to have the current representation over a period of time this model does not work. In HTTP, this has been solved using repeated polling or HTTP long polling RFC6202 but the added complexity makes it hard in the constrained space.
In CoAP, this has been solved by using the Observe option. As we saw, CoAP allows to define new options to extend the protocol. This one is added to the GET method to request the server to add/remove a client from a list of observers of a resource. The value of the Observe option is either 0 for register or 1 for deregister.
If the servers returns a successful response (2.xx) with the Observe option as well, then that means the server has added the client to the list of observers of the target resource and the client will be notified of changes to the resource. Links to resources that are observable may include the attribute obs to indicate that. This is an attribute of a link, which will be explained in CoAP Web Linking and Serialization.
Another important option is Max-Age, which indicates how long the data can be served from a cache in seconds. For example, a CoAP client could request for a temperature resource and use the Observe option with value 0 to get subsequent notifications. The CoAP server will send a notification every time the resource value changes and use the Max-Age option to indicate that the data will be stale after a certain time period. This is shown in the following example.
REQ: GET coap://coap.me:5683/sensors/temp1
observe:0 | token: 0x4a
RES: 2.05 Content
observe:9 | token: 0x4a | Max-Age: 15
[{"u":"C","v":25.2}]
RES: 2.05 Content
observe:16 | token: 0x4a | Max-Age: 15
[{"u":"C","v":27.1}]
After these two notifications were sent, it might happen that third message is lost. Since the Max-Age of the data is 15 seconds, the Client will notice that the data is stale, at which point it might choose to register again or to wait for the next notification.
RES (LOST MESSAGE): 2.05 Content
observe:25 | token: 0x4a | Max-Age: 15
[{"u":"C","v":19.7}]
--- 15 seconds pass ---
REQ: GET coap://coap.me:5683/sensors/temp1
observe:0 | token: 0xb2
RES: 2.05 Content
observe:44 | token: 0xb2 | Max-Age: 15
[{"u":"C","v":18.4}]
It can be important to have reliability for some resources therefore some requests can use confirmable (CON) messages. A server might also use a confirmable response every Nth message to make sure that the client is still interested in the information, but use non-confirmable responses in most cases. The example below uses Max-Age = 15 and a first timeout of usually from 2 seconds (note that the timeout has an algorithm to calculate the right value). In this case there is a retransmission before the freshness of the data expires.
REQ: GET (T=CON) coap://coap.me:5683/sensors/temp1
observe:0 | token: 0x4a
RES: (LOST MESSAGE) 2.05 Content
observe:25 | token: 0x4a | Max-Age: 15
[{"u":"C","v":19.7}]
--- 2 seconds pass and retransmission timeout triggers ---
RES: 2.05 Content
observe:25 | token: 0x4a | Max-Age: 15
[{"u":"C","v":19.7}]
CoAP Web Linking and Serialization
Web Linking is a fundamental part of any REST protocol, and it is the feature that makes it more versatile and flexible when compared with other alternative technologies. In CoRE, linking is defined by RFC6690 in a similar way as HTTP defines it in RFC5988. URI's are defined in RFC3986. We will see some of the basic concepts in this chapter.
URIs
We will briefly have to explain what a URI is as it is probably very intuitive since it is part of our daily HTTP browsing. Everyone can recognize the following syntax of the URI scheme.
foo://example.com:8042/over/there?name=ferret#nose
\_/ \_______________/\________/\__________/\___/
| | | | |
scheme authority path query fragment
A URI can be classified as a locator, a name, or both. Uniform Resource Locator (URL) refers to URIs that allow for identification and location of a resource by describing how to access it on a network. Uniform Resource Name (URN) are used as globally unique identifiers. Universally Unique IDentifier (UUID) are unique and persistent URNs that do not require a central registration authority.
The URI format is used on pretty much any application protocol in existence, from FTP, HTTP or telnet to CoAP. Some with little variations in the syntax, like that of the email mailto or the telephone tel, as you can see below.
tel : +34-690-555-1212
mailto : infobot@example.com ?subject=issue
urn:uuid: f81d4fa...a0c91e6bf6
ftp :// 196.4.160.12 /rfc/rfc1808.txt
http :// www.ietf.org /rfc/rfc2396.txt
\______/ \__________________/ \___________________/\___________/
| | | |
scheme authority path query
The CoAP URI is similar: "coap:" "//" host [ ":" port ] path-abempty [ "?" query ], the examples below show several usages of it. You can try some yourself at coap.me.
coap://sensor.iot.org:5683 /lamp ?rt=light-lux#rec=3
coap://[2001:db8:::1]:5683 /temperature ?ct=60
coap://coap.me:5683 /.well-known/core
\__/ \_________________/\______________/\__________/\___/
| | | | |
scheme authority path query fragment
Media Types
In addition to URIs, it is important to know other concepts used in REST applications and systems. In particular concepts like media-types, content-types, and content coding. There is a very good clarification document,
-
Media Type: Media types are registered in the IANA Media Types registry. They identify the general
typelike "audio" or "text" combined with asubtypelike "ogg", "plain", or "html", resulting in strings like "audio/ogg", "text/plain", and "text/html". In IoT, common media types are used for applications that consume the information like "application/senml+cbor" or "application/link-format". Media-Types are registered in IANA. -
Content Type: Content types are used in HTTP to specify a media type, optionally associated with additional, media type-specific parameters (separated from the media type and each other by semicolons).
-
Content Coding: Content codings are registered in the IANA HTTP Parameters registry and identify an optional transformation to the representation of a resource, such as the compression or encryption of some data.
-
Content Format: Content formats are used in CoAP to identify the combination of a content type and a content coding. They are registered in the IANA CoAP Content-Formats registry.
For example, the content-format 11060 identifies the content type application/cbor (defined by RFC7049) combined with the content coding deflate (defined by RFC7049).
At this point, we are capable of having applications point to specific locations using URLs, indicating concrete protocols used to get resources, and serving those resources in a specific format.
Just like a web browser understands HTTP and the common media types for HTML text/html and images image/jpeg, an IoT client could understand CoAP and common media types like application/cbor, which implies data will be send in CBOR format.
Link Attributes
A commonly confused term is link or target attributes, which are defined in RFC6690 and RFC5988 and describe information useful to be added to a target link. They are hints indicating information about the link. In HTTP "media" for example indicates the destination medium, "rel" specifies the relation with another link, and so on.
In CoAP link attributes can define some properties of a device, for example the Open Interconnect Consortium (OIC) defines resource type "rt" link attributes that help understand which type of device is behind the link, like "oic.d.fan" or "oic.d.light". They use a urn-like type of format. Another link attribute that is used today is interface description "if" which lets the client know that the link points to an interface of some kind.
Data Serialization
We have explained how resources exposed by a CoAP Server can be addressed using URIs and how the client can tell the server how content is to be presented and which format to use. We have even mention how that content can be serialized, that is how it is sent on the wire, by using CBOR. While CBOR is binary and hard to read without translation tools for humans, there is a serialization format called SenML that is much readable.
SenML can be represented in various formats with their respective media types which are: application/senml-exi , application/senml+cbor , application/senml+json , application/senml+xml. We will use JSON as it is one of the most common and it is easily readable - and writable - in this document. To illustrate with an example, we have the following exchange between two CoAP endpoints.
The CoAP client will request the resources available under the path /device. The request asks for the content format identifier of 110, which means application/senml+json without any additional content coding.
REQ: GET coap://coap.me:5683/device?ct=110
The response below uses the CoAP code of 2.05, which means that the operation was successful The payload contains a times series of measurements with the base name bn indicating the URN of the device, the base time bt when the time series started, the units bu and the version used ver of 2.
After the base values there is the individual measurements containing the field name n either current or voltage, the time it was measured t , which is negative for historical data before the base measurement. The SenML output would look like the one below:
RES: 2.05 Content
[ {"bn":"urn:dev:mac:0024befffe804ff1/","bt":1276020076,"bu":"A","ver":2},
{"n":"voltage","u":"V","v":0},
{"n":"current","t":-4,"v":1.3},
{"n":"current","t":-3,"v":1,"s":33.44},
{"n":"current","v":1.7}
]
At first glance, it looks like JSON and is easily understandable by humans. However, given that we have constrains in bandwidth, it would be very useful to have a data format that, among other features, is much smaller in message size. For that purpose the Concise Binary Object Representation (CBOR) was created. Below you can see the same payload in CBOR in only 147 Bytes.
00000000: 85a4 2178 1d75 726e 3a64 6576 3a6d 6163 ..!x.urn:dev:mac
00000010: 3a30 3032 3462 6566 6666 6538 3034 6666 :0024befffe804ff
00000020: 312f 221a 4c0e 856c 2361 4163 7665 7202 1/".L..l#aAcver.
00000030: a300 6776 6f6c 7461 6765 0161 5602 00a3 ..gvoltage.aV...
00000040: 0067 6375 7272 656e 7406 2302 fb3f f4cc .gcurrent.#..?..
00000050: cccc cccc cda4 0067 6375 7272 656e 7406 .......gcurrent.
00000060: 2202 0105 fb40 40b8 51eb 851e b8a2 0067 "....@@.Q......g
00000070: 6375 7272 656e 7402 fb3f fb33 3333 3333 current..?.33333
00000080: 33 3
Finding your CoAP devices
While we have explained how data is transmitted and how it looks like and we do have URLs to share the location of our CoAP devices, we have to figure out how to find CoAP devices to begin with and, once we know the URL of a CoAP device, how do we know what is on that device.
Discovery steps
There are quite a few steps needed in order to retrieve that particular temperature measurement we are looking for. At a high level they are:
- Find a Resource Directory (RD).
GET coap://[FF0X::FE]/.well-known/core?rt=core.rd*
- Find the Lookup Interface of the RD.
GET coap://rd.jaime.win/.well-known/core?rt=core.rd-lookup-res
- Find an endpoint or a temperature resource (for example) Registered in the RD.
GET coap://rd.jaime.win/rd-lookup/res?rt=temperature
- Query that Endpoint for the
/.well-known/coreresource in order to see what's there.
GET coap://[2001:db8:3::123]:5683/.well-known/core?rt=temperature
- Query the specific resource you are looking for in order to get the current representation.
GET coap://[2001:db8:3::123]:5683/sensors/temp1
After this last query you would get back the current value of the temperature. Of course, this series of requests are done only the first time a client connects, when we know nothing about the network or the devices that are in it.
Discovering Resources
Let's start with the second question first, how do you find the resources that a device has before asking it for them? Indeed, if we do not have any idea of what the device is supposed to do, it would be impossible to query for anything as we would not know the path part of the URL. To fix that problem, CoAP endpoint can come with a default URI that everyone knows, the "well-known" URI.
When using CoRE Link Format, this URI is called /.well-known/core. That way, a CoAP client can send a GET request to a CoAP server for /.well-known/core and get in return a list of hypermedia links to other resources hosted in that server. Moreover, it can also filter the output to limit the amount of responses with a query string. For example we could query a CoAP server for all resources of the type temperature.
REQ: GET coap://coap.me:5683/.well-known/core?rt=temperature
RES: 2.05 Content
</sensors/temp1>;rt="temperature",
</sensors/temp2>;rt="temperature",
Once the client knows that there are two sensors of the type temperature, it can decide to follow one of the presented links and query it, for example the first one /sensors/temp1. That way it can find the current value of the resource as we learnt in the previous section.
REQ: GET coap://coap.me:5683/sensors/temp1
RES: 2.05 Content
[{"n":"urn:dev:ow:10e2073a01080063","u":"Cel","v":23.1}]
Discovering CoAP Endpoints
We have explained how to discover the resources on a CoAP endpoint but we have not mentioned how endpoints can be found to begin with.
Networks are and will continue to be heterogeneous, some scenarios foresee the use of multicast, while others have a master/slave approach. Some scenarios will have NATs and firewalls while other - more ideal - will simply have globally addressable IPv6 addresses. Some devices will be asleep while others will be permanently connected.
In scenarios where direct discovery of resources is not possible due to sleeping nodes, disperse networks or inefficiency of multicast it is possible to store information about resources held on other servers on something called a Resource Directory (RD).
Registration Lookup
Interface Interface
+----+ | |
| EP |---- | |
+----+ ---- | |
--|- +------+ |
+----+ | ----| | | +--------+
| EP | ---------|-----| RD |----|-----| Client |
+----+ | ----| | | +--------+
--|- +------+ |
+----+ ---- | |
| CT |---- | |
+----+
RD has two interfaces, one for registration and another for lookup. To start using either fo them we first we need to find the RD. There are several options:
- Already knowing the IP address. Which means that devices need to be configured with that IP, this is the most common setup.
- Using a DNS name for the RD and use DNS to return the IP address of the RD. Which means that devices need to be configured with the domain name (e.g.,
rd.jaime.win). - Multicast request all RDs in the same multicast group. More on that below.
- It could be configured using DNS Service Discovery (DNS-SD)
- It could be provided by default from the network using IPv6 Neighbor Discovery by carrying information about the address of the RD, there is a Resource Directory Address Option (RDAO) for it.
After performing the discovery you should get the URI of the resource directory like coap://rd.jaime.win
Registration
After discovering the RD a CoAP device can register its resources in it. A minimal registration will contain some endpoint identifier ep, the content format identifier which is 40 in this case (i.e., application/link-format) as well as a series of links resources that the endpoint wants to register.
REQ: POST coap://rd.jaime.win/rd?ep=node1
ct:40
</sensors/temp>;ct=41;rt="temperature-c";if="sensor";
</sensors/light>;ct=41;rt="light-lux";if="sensor"
The RD will return 2.01 (Created) response with the location path of the entry in the directory, in this case /rd/4521. That location is used in all subsequent operations on that registration.
RES: 2.01 Created
Location-Path: /rd/4521
There are several alternatives, like delegating registration to a commissioning tool, requesting the RD to fetch the links from the endpoint and others that are detailed in the RD specification.
Lookup
To discover the resources registered with the RD an endpoint can use the lookup interface, which allows lookups for endpoints and resources using known CoRE Link attributes and two additional resource types (rt): core.rd-lookup-res for resources and core.rd-lookup-ep for endpoints.
You will have to ask the RD for its configuration to get which is the path where we can perform lookup, we could ask for all available interfaces by querying /.well-known/core with the query rt=core.rd*.
REQ: GET coap://rd.jaime.win/.well-known/core?rt=core.rd*
RES: 2.05 Content
</rd>;rt="core.rd";ct=40,
</rd-lookup/ep>;rt="core.rd-lookup-ep";ct=40,
</rd-lookup/res>;rt="core.rd-lookup-res";ct=40,
However, in in this case we just want to find CoAP resources, therefore we query rt=core.rd-lookup-res. The RD returns the lookup interface for resources /rd-lookup/res.
REQ: GET coap://rd.jaime.win/.well-known/core?rt=core.rd-lookup-res
RES: </rd-lookup/res>;rt="core.rd-lookup-res";ct=40
Once we have the entry point to query the RD we could ask for all links to temperature resources in it with the query parameter rt=temperature.
REQ: GET coap://rd.jaime.win/rd-lookup/res?rt=temperature
The RD will return a list of links that host that type of resource.
RES: 2.05 Content
<coap://[2001:db8:3::123]:61616/temp>;rt="temperature";
anchor="coap://[2001:db8:3::123]:61616"
<coap://[2001:db8:3::124]/temphome1>;rt="temperature";
anchor="coap://[2001:db8:3::124]",
<coap://[2001:db8:3::124]/temphome2>;rt="temperature";
anchor="coap://[2001:db8:3::124]",
<coap://[2001:db8:3::124]/temphome3>;rt="temperature";
anchor="coap://[2001:db8:3::124]"
You can perform Observe on the Resource Directory in order to see when new links are registered, a very useful feature.
Use of Multicast in CoAP
There is an added benefit of using UDP: A CoAP client can use UDP multicast to broadcast a message to every machine on the local network.
In some home automation cases, all devices will be under the same subnet, your thermostat, refrigerator, television, light switches, and other home appliances have cheap embedded processors that communicate over a local low-power network. This lets your appliances coordinate their behavior without direct input from you. When you turn the oven on, the climate control system can notice this event and turn down the heat in the kitchen. You can pull out your mobile phone, get a list of all the lights in your current room, and dim the lights through your phone, without having to go over to the light switch.
CoRE has registered one IPv4 and one IPv6 address each for the purpose of CoAP multicast. All CoAP Nodes can be addressed at 224.0.1.187 and at FF0X::FD. Nevertheless, multicast must be used with care as it is easy to create complex network problems involving broadcasting. You could do a discovery for all CoAP endpoints with:
GET coap://[FF0X::FD]/.well-known/core
In a network that supports multicast well, you can discover the RD using a multicast query for /.well-known/core and the query parameter ?rt=core.rd*. IANA has not yet decided on the multicast address to be reserved but we can assume that all CoRE RDs can be found at the IPv4 224.0.1.187 and an additional IPv6 multicast group address FF0X::FE will be created in order to limit the burden on other CoAP Endpoints. The request would then be:
GET coap://[FF0X::FE]/.well-known/core?rt=core.rd*
Notice that in the first example every CoAP endpoint will reply and in the second only those supporting RD.
Security Engineering
There is a wealth of literature on the topic of Internet and Systems Security, but Security Engineering by Ross Anderson in particular is a great authoritative and readable source, it is also free. Also Dave Dittrich's website on DDOS with hundreds of examples and pointers.
It would be too time consuming to go through all potential Internet attacks and IoT security vulnerabilities here. We will focus on one type, the Distributed Denial-of-Service (DDOS) Attack in the context of IoT and CoAP.
Distributed Denial-of-service (DDOS) Attacks
The purpose of any denial-of-service attack is to limit the availability of a service. A DDOS attack tries to disrupt a machine in the network, preventing it to fullfil its service by flooding it with traffic from many different sources until the resources of the target are exhausted (i.e., memory, processing capabilities, or Internet bandwidth). This effectively makes it impossible to stop the attack simply by blocking a single source.
Distributed denial-of-service (DDoS) attacks came to public notice when they were used to bring down Panix, a New York ISP, for several days in 1996. Over time it popularized, being used even to hit 6 out of the 13 ROOT DNS servers back in 2007.
DDOS has become a mechanism for extorsion, using DDOS to blackmail ISPs or Internet Services. The modus operandi consists on assembling a botnet and flooding a target webserver with traffic until its owner paid them to desist. While originally substantial sums were paid (e.g., $10,000–$50,000) nowadays the process has been simplified to the point that marketplaces to hire DDOS services exist. The services are as cheap as 15€ a month.
The existence of outdated IoT devices is also a great breeding ground for more attacks, as 2016 Mirai's botnet, used to perform very large (600Gps) DDOS attacks using an average of 300.000 infected devices (i.e., DVRs, IP cameras, routers, and printers) and as many as 600000.
Using UDP-based protocols
Although Mirai's attack was using TCP protocols to attack, it required compromising the host before hand. With UDP attacks you can get high amplification factors without the need to hack anything.
UDP is a simple, connection-less transport protocol. It has no handshaking and no dedicated end-to-end connection, therefore there is no guarantee of delivery. Being so small it is very lightweight while also providing multicast possibility; both features are very useful in the IoT context where normally the communication ar small messages with few requests and responses.
There are some drawbacks of using UDP though as it leaves the door open to two types of attacks: IP Address Spoofing and Packet Amplification
IP Address Spoofing
The UDP header consists of 4 fields [source and destination ports, length and checksum], each of which is 2 bytes being then the header 8 bytes in total. After that we have the 20 byte IP header which contains, among other things version, source and destination address. If we want to avoid packet fragmentation that leaves about 1280B for IPv6 and 576 for IPv4. A rudimentary IPv6 packet would be:
+---------------------------------------------+
| 40B IPv6 | 8B UDP | 1024 bytes payload |
+---------------------------------------------+
The IP Spoofing attack consists on an attacker sending such IP packet but with a spoofed source IP address. That fake address being the address of the victim.
Attacker: IP = 1.1.1.1
| +-------------------------------------------+
| | IPs 3.3.3.3 , IPd 2.2.2.2 | UDP | Payload |
| +-------------------------------------------+
v
Intermediary: IP = 2.2.2.2
| +-------------------------------------------+
| | IPs 2.2.2.2 , IPd 3.3.3.3 | UDP | Payload |
| +-------------------------------------------+
v
Victim: IP = 3.3.3.3
IP Spoofing over UDP is particularly easy as the Attacker does not require any information about the communication between the Intermediary and the Victim. Over TCP the Attacker would somehow have to sit between the Intermediary and the Victim in order to forge the IP address as there is a connection establishment handshake.
Packet Amplification
Packet amplification is another potential attack carried out over UDP-based application protocols that implement some form of request/response mechanism. The dynamics are simple and it is used together with IP Spoofing.
IP Spoofed Large
Request +---------+ Response
+----------> | Interm +------------+
| +---------+ |
| v
+----------+ | +---------+ +---+----+
| Attacker +--+----------> | Interm +------->+ Victim |
+----------+ | +---------+ +---+----+
| ^
| +---------+ |
+----------> | Interm +------------+
+---------+
The attacker will use Intermediary nodes as to craft a request that will generate a large response from them. That response will go to the Spoofed Address of the Victim. Depending on the amplification factor an attacking machine could amplify 1MBps on the first machine to number-of-devices * (1 MBps * Amplification Factor).
DDOS using CoAP
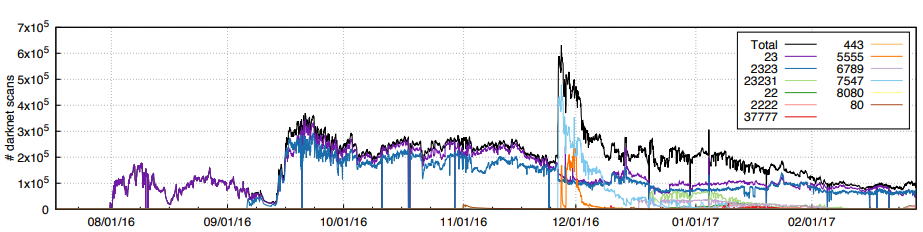
That CoAP can be used in malicious DDOS attacks is news but at the same time it is not. Already when the CoAP RFC was published it came with a Security Section with that caveat in mind, being UDP a choice made to process message faster and scale better. Today, CoAP is now deployed widely enough to be more than noticeable by malicious attackers as shown in 1 , 2 , 3 and 4.
As CoAP becomes more mainstream, it is likely that there will be more attacks taking advantage of misconfigured endpoints. In fact CoAP has already been "occasionally used as a basis of DDOS attacks, with increasing frequency, reaching 55Gbps on average, and with the largest one clocking at 320Gbps". Apparently the attacks are short-lived, lasting on average "just over 90 seconds" and feature around 100 packets per second.
An attack of 320Gbps is already huge, since as we saw On DDOS Attacks Mirai clocked at 600Gbps. It is thus not unlikely that a 1Tbps attack using CoAP may occur relatively soon. The current peak volume clocked in an attack is of some 1.7Tbps of malicious traffic.
As a danish researcher at RVAsec points out, the CoAP protocol was not yet mainstream back in 2017, but the number of visible CoAP endpoints has increased rapidly from about 6500 to 220000 between november 2017 and may 2018, to more than 738041 in October 2018.
That number has decreased as devices are being patched and today we would find about 436854 running :~$ shodan count port:5683, out of which 305051 are in China. There are of course orders of magnitude more endpoints that are not openly visible on the Internet.
These attacks are based on the two vulnerabilities of UDP-based protocols mentioned in the previous section.
IP Address Spoofing
There are two main types of transports on the Internet, TCP and UDP. TCP is connection oriented, which means that it is bidirectional between sender and receiver. In TCP there is a handshake -the famous three-way handshake- so that both sender and receiver confirm that they are able to communicate and that they are in sync. In UDP however there is no handshake and know explicit acknowledgment of the communication, information flows in one direction.
UDP then is vulnerable to IP spoofing, which consists on forging the header of the IP packet so that the IP address of the sender is different from that of the machine who sent it, being instead that of the victim machine. The receiver of the packet -another victim- will send the response to the spoofed address. In CoAP every server is expected to reply to some GET requests to specific resources, making it easy to guess which is the payload that the request has to contain.
Due to the lack of handshake in UDP, RFC 7252, Section 11.4, warns that there are some message types that can be spoofed on unsecured CoAP networks. They can range from simple, like a RST or an ACKin response to a CON message which would cause an error in the communication, to disruptive when spoofing a multicast request (cause CoAP does support multicast) for a target node. This may result in a DOS to a victim or in the congestion/collapse of the network.
Moreover under this attack, a constrained node with limited total energy available may exhaust that energy much more quickly than planned (battery depletion attack).
Amplification
As it is explained on RFC, 7252 Section 11.3, CoAP responses might be - and usually are - larger than their request. Think for example GET /.well-known/core that returns links to all resources, or a query to a complex sensor that returns a large JSON payload. I can imagine that if the Observe option is 0 then notifications to the victim would be sent automatically, increasing the length of the attack. Also if the crafted request asks for text-based ct the response would be larger than binary ones.
The RFC then states: "This is particularly a problem in nodes that enable NoSec access, are accessible from an attacker, and can access potential victims (e.g., on the general Internet), as the UDP protocol provides no way to verify the source address given in the request packet".
CoAP Amplification Factor
The table below is inspired from Dennis Radd presentation contains some common UDP protocols used on DDOS, the total number of endpoints available on Shodan (available at April 2019) out of which an unknown (to me) percentage will be open for an attack. The request size and amplification factor is taken from the presentation and from CISA.
The amplification factor means represents the effort for an attacker, for example in CoAP a request of 21 bytes without the UDP header of size can yield a response of 21*16= 336 bytes. The target for the attacker is to use the minimum effort for the maximum attack factor. An attacker who has access to a 1 Mbps link could on average reach 16 Mbps and up to 97 Mbps per endpoint.
| Protocol (port) | Request size | Avg/Max amplification | Numbers |
|---|---|---|---|
| DNS (53) | 37 b | 28/54 | 13.986.243 |
| NetBIOS (137) | 50 b | 3/229 | 601.869 |
| SIP (5060) | 128 b | 3/19 | 15.161.110 |
| SNPM (161) | 40 b | 34/553 | 2.184.406 |
| NTP (123) | 12 b | 22/198 | 9.483.324 |
| CoAP (5683) | 21 b | 16/97 | 436.854 |
| LDAP (389) | 52 b | 45/55 | 494.276 |
| Memcached (11211) | 15 b | 73/51000 (!!) | 39.785 |
Exploring Vulnerable Endpoints
Shodan and nmap are the preferred tools to find out about existing vulnerable CoAP endpoints, however the usability of the first one is limited without a paid account.
Some of Shodan's most basic commands are:
| Shodan Command | Effect |
|---|---|
shodan host [IP_ADDRESS_HERE] | get info on a specific endpoint |
shodan count port:5683 country:CN | get all CoAP endpoints in China |
shodan stats --limit 20 port:5683 | get some statistics CoAP endpoits out there |
shodan search --fields ip_str,port,org,hostnames port:5683 country:CN | get a list of CoAP endpoints, their specific IPs and hostname |
There is also a web interface that allows for searching, for example CoAP endpoints. Looking a bit more on a couple of aleatory searched hosts shows two CoAP endpoints that potentially are discoverable over the Internet and vulnerable to UDP-based attacks. We can search them by issuing :~$ shodan host 120.212.XXX.XXX
As we saw in the section Finding your CoAP devices CoAP has an in-built discovery mechanism, thus sending a GET request message to the /.well-known/core resource might show information. Indeed, for example:
-
The node in Novgorod shows the available resources, examples of the expected payloads and the interaction methods.
-
Similarly the node in Nanchang exposes network information, interfaces and all resources available, some even related to control information and the expected content-formats or passwords.
If we were interested which type of devices are these , it is easy to perform an nmap scan to find out that several other TCP ports are also open, indicating that at least a portion of the devices are gateways with a dozen other services.
Solutions
As we other DDOS attacks, some solutions are already at hand, some outlined in RFC 4732, others on RFC 7252 and on draft-irtf-t2trg-iot-seccons. The guidelines to be followed when implementing and deploying CoAP networks that help prevent and palliate DOS attacks would be:
- Avoiding the use of
NoSecmode, using instead any of the other secure modes. - Avoid exposing CoAP endpoints to the wider Internet if they don't need to.
- Using a randomized
tokenvalue. - When using
CONmessages we can detect unexpectedACKRSTfrom the deceived endpoint. However it is costly and not always feasible. - Verify every now and then that observations are still valid by sending a
CONfrom the observed CoAP resource. - Limiting the response rate can also palliate the problem.
- Routers and middleboxes have high bandwidth, which is a scarce resource in the case of constrained networks. That will be a mitigating factor, making CoAP nodes less attractive for this attack.
- Large amplification factors should not be provided if the request is not authenticated.
- CoAP servers should not accept multicast requests that can not be authenticated in some way
- Ensure all default passwords are changed to strong passwords.
- Update IoT devices with security patches as soon as patches become available.
- Network operators could prevent the leakage of packets with forged source addresses by following the guidelines of RFC 2827.
Nevertheless, as it is pointed out in Another 10 years:
The Internet of Things will continue to be a market place where the compromises between price and quality will continue to push us on to the side of cheap rather than secure.
Bonus: Richard Thieme - Staring into the Abyss
CoAP-Explorer
It is a work-in-progress project to help researchers understand potential CoAP DDOS.
More on: http://research.coap-explorer.realmv6.org/
More information
Below are some excelent references that are worth reading:
- A decade of Internet Evolution was published in the Internet Protocol Journal on June 2009 - Volume 11, number 2. Author is Vint Cerf.
- Another 10 years was published in the Internet Protocol Journal on August 2018 - Volume 21, number 2. Author is Geoff Huston.
A decade of Internet Evolution
This is an article published in the Internet Protocol Journal on June 2009 - Volume 11, number 2, written by Vint Cerf.
In 1998 the Internet had about 50 million users, supported by approximately 25 million servers (Web and e-mail hosting sites, for example, but not desktops or laptops). In that same year, the Internet Corporation for Assigned Names and Numbers (ICANN) was created. Internet companies such as Netscape Communications, Yahoo!, eBay, and Amazon were already 3 to 4 years old and the Internet was in the middle of its so-called "dot-boom" period. Google emerged that year as a highly speculative effort to "organize the world's information and make it accessible and useful." Investment in anything related to the Internet was called "irrational exuberance" by the then head of the U.S. Federal Reserve Bank, Alan Greenspan.
By April 2000, the Internet boom ended—at least in the United States—and a notable decline in investment in Internet application providers and infrastructure ensued. Domino effects resulted for router vendors, Internet service providers, and application providers. An underlying demand for Internet services remained, however, and it continued to grow, in part because of the growth in the number of Internet users worldwide.
During this same period, access to the Internet began to shift from dial-up speeds (on the order of kilobits to tens of kilobits per second) to broadband speeds (often measured in megabits per second). New access technologies such as digital subscriber loops and dedicated fiber raised consumer expectations of Internet capacity, in turn triggering much interest in streaming applications such as voice and video. In some locales, consumers could obtain gigabit access to the Internet (for example, in Japan and Stockholm). In addition, mobile access increased rapidly as mobile technology spread throughout the world, especially in regions where wireline telephony had been slow to develop.
Today the Internet has an estimated 542 million servers and about 1.3 billion users. Of the estimated 3 billion mobile phones in use, about 15 percent are Internet-enabled, adding 450 million devices to the Internet. In addition, at least 1 billion personal computers are in use, a significant fraction of which also have access to the Internet. The diversity of devices and access speeds on the Internet combine to produce challenges and opportunities for Internet application providers around the world. Highly variable speeds, display areas, and physical modes of interaction create a rich but complex canvas on which to develop new Internet applications and adapt older ones.
Another well-documented but unexpected development during this same decade is the dramatic increase in user-produced content on the Internet. There is no question that users contributed strongly to the utility of the Internet as the World Wide Web made its debut in the early 1990s with a rapidly growing menu of Web pages.
But higher speeds have encouraged user-produced audio and video archives (Napster and YouTube), as well as sharing of all forms of digital content through peer-to-peer protocols. Voice over IP, once a novelty, is very common, together with video conferencing (iChat from Apple, for example).
Geographically indexed information has also emerged as a major resource for Internet users. In the scientific realm, Google Earth and Google Maps are frequently used to display scientific data, sensor measurements, and so on. Local consumer information is another common theme. When I found myself in the small town of Page, Arizona, looking for saffron to make paella while in a houseboat on Lake Powell, a Google search on my Blackberry quickly identified markets in the area. I called one of them and verified that it had saffron in stock. I followed the map on the Website and bought 0.06 ounces of Spanish saffron for about $12.99. This experience reinforced my belief that having locally useful information at your fingertips no matter where you are is a powerful ally in daily living.
New business models based on the economics of digital information are also emerging. I can recall spending $1,000 for about 10 MB of disk storage in 1979. Recently I purchased 2 TB of disk storage for about $600. If I had tried to buy 2 TB of disk storage in 1979, it would have cost $200 million, and probably would have outstripped the production capacity of the supplier. The cost of processing, storing, and transporting digital information has changed the cost basis for businesses that once required the physical delivery of objects containing information (books, newspapers, magazines, CDs, and DVDs). The Internet can deliver this kind of information in digital form economically—and often more quickly than physical delivery. Older businesses whose business models are based on the costs of physical delivery of information must adapt to these new economics or they may find themselves losing business to online competitors. (It is interesting to note, however, that the Netflix business, which delivers DVDs by postal mail, has a respectable data rate of about 145 kbps per DVD, assuming a 3-day delivery time and about 4.7 GB per DVD. The CEO of Netflix, Reed Hastings, told me nearly 2 years ago that he was then shipping about 1.9 million DVDs per day, for an aggregate data rate of about 275 Gbps!)
Even the media that have traditionally been delivered electronically such as telephony, television, and radio are being changed by digital technology and the Internet. These media can now be delivered from countless sources to equally countless destinations over the Internet. It is common to think of these media as being delivered in streaming modes (that is, packets delivered in real time), but this need not be the case for material that has been prerecorded. Users of iPods have already discovered that they can download music faster than they can listen to it.
With gigabit access to the Internet, one could download an hour's worth of conventional video in about 16 seconds. This fact certainly changes my understanding of "video on demand" from a streaming delivery to a file transfer. The latter is much easier on the Internet because one is not concerned about packet inter-arrival times (jitter), loss, or even orderly delivery because the packets can be reordered and retransmitted during the file transfer. I am told that about 10 hours of video are being uploaded to YouTube per second.
The battles over Quality of Service (QoS) are probably not over yet either. Services such as Skype and applications such as iChat from Apple demonstrate the feasibility of credible, real-time audio and video conferencing on the "best-efforts" public Internet. I have been surprised by the quality that is possible when both parties have reasonably high-capacity access to the Internet.
Technorati is said to be tracking on the order of 112 million blogs, and the China Internet Network Information Center (CNNIC) estimates 72 million Chinese blogs that are probably in addition to those tracked by Technorati. Adding to these are billions of Web pages and, perhaps even more significant, an unknown amount of information online in the form of large databases. The latter are not indexed in the same way that Web pages can be, but probably contain more information. Think about high-energy physics information, images from the Hubble and other telescopes, radio telescope data including the Search for Extra-Terrestrial Intelligence (SETI), and you quickly conclude that our modern society is awash in digital information.
It seems fair to ask how long accessibility of this information is likely to continue. By this question I do not mean that it may be lost from the Internet but, rather, that we may lose the ability to interpret it. I have already encountered such problems with image files whose formats are old and whose interpretation by newer software may not be possible. Similarly, I have ASCII text files from more than 20 years ago that I can still read, but I no longer have operating software that can interpret the formatting instructions to produce a nicely formatted page. I sometimes think of this problem as the "year 3000" problem: It is the year 3000 and I have just finished a Google search and found a PowerPoint 1997 file. Assuming I am running Windows 3000, it is a fair question whether the format of this file will still be interpretable. This problem would arise even if I were using open-source software. It seems unlikely that application software will last 1000 years in the normal course of events unless we deliberately take steps to preserve our ability to interpret digital content. Absent such actions, we will find ourselves awash in a sea of rotting bits whose meaning has long since been lost.
This problem is not trivial because questions will arise about intellectual property protection of the application, and even the operating system software involved. If a company goes out of business or asserts that it will no longer support a particular version of an application or operating system, do we need new regulations that require this software to be available on the public Internet in some way?
Even if we have skirted this problem in the past by rendering information into printed form, or microfilm, the complexity of digital objects is increasing. Consider spreadsheets or other complex objects that really cannot be fully "rendered" without the assistance of application software. So it will not be adequate simply to print or render information in other long-lived media formats. We really will need to preserve our ability to read and interpret bits.
The year 2008 also marks the tenth anniversary of a project that started at the U.S. Jet Propulsion Laboratory: The Interplanetary Internet. This effort began as a protocol design exercise to see what would have to change to make Internet-like capability available to manned and robotic spacecraft. The idea was to develop networking technology that would provide to the space exploration field the kind of rich and interoperable networking between spacecraft of any (Earth) origin that we enjoy between devices on the Internet.
The design team quickly recognized that the standard TCP/IP protocols would not overcome some of the long delays and disruptions to be expected in deep space communication. A new set of protocols evolved that could operate above the conventional Internet or on underlying transport protocols more suited to long delays and disruption. Called "delay and disruption tolerant networking" or DTN, this suite of protocols is layered in the same abstract way as the Internet. The Interplanetary system could be thought of as a network of Internets, although it is not constrained to use conventional Internet protocols. The analog of IP is called the Bundle Protocol, and this protocol can run above TCP or the User Datagram Protocol (UDP) or the new Licklider Transport Protocol (for deep space application). Ironically, the DTN protocol suite has also proven to be useful for terrestrial applications in which delay and disruption are common: tactical military communication and civilian mobile communication.
After 10 years of work, the DTN system will be tested onboard the Deep Impact mission platform late in 2008 as part of a program to qualify the new technology for use in future space missions. It is hoped that this protocol suite can be standardized for use by any of the world's space agencies so that spacecraft from any country will be interoperable with spacecraft of other countries and available to support new missions if they are still operational and have completed their primary missions. Such a situation already exists on Mars, where the Rovers are using previously launched orbital satellites to relay information to Earth's Deep Space Network using store-and-forward techniques like those common to the Internet.
The Internet has gone from dial-up to deep space in just the past 10 years. One can only begin to speculate about its application and condition 10 years hence. We will all have to keep our subscriptions to The Internet Protocol Journal to find out!
Another 10 Years Later
This is an article published in the Internet Protocol Journal on August 2018 - Volume 21, number 2. It was written by Geoff Huston who is Chief Scientist at APNIC, the Regional Internet Registry serving the Asia-Pacific region.
The evolutionary path of any technology can often take strange and unanticipated turns and twists. At some points simplicity and minimalism can be replaced by complexity and ornamentation, while at other times a dramatic cut-through exposes the core concepts of the technology and removes layers of superfluous additions. The evolution of the Internet appears to be no exception and contains these same forms of unanticipated turns and twists. In thinking about the technology of the Internet over the last ten years, it appears that it’s been a very mixed story about what’s changed and what’s stayed the same.
A lot of the Internet today looks much the same as the Internet of a decade ago. Much of the Internet’s infrastructure has stubbornly resisted various efforts to engender change. We are still in the middle of the process to transition the Internet to IPv6, which was the case a decade ago. We are still trying to improve the resilience of the Internet to various attack vectors, which was the case a decade ago. We are still grappling with various efforts to provide defined quality of service in the network, which was the case a decade ago. It seems that the rapid pace of technical change in the 1990’s and early 2000’s has simply run out of momentum and it seems that the dominant activity on the Internet over the past decade was consolidation rather than continued technical evolution. Perhaps this increased resistance to change is because as the size of the network increases, its inertial mass also increases. We used to quote Metcalf’s Law to each other, reciting the mantra that the value of a network increases in proportion to the square of the number of users. A related observation appears to be that a network’s inherent resistance to change, or inertial mass, is also directly related to the square of the number of users as well. Perhaps as a general observation, all large loosely coupled distributed systems are strongly resistant to efforts to orchestrate a coordinated change. At best, these systems respond to various forms of market pressures, but as the Internet’s overall system is so large and so diverse these market pressures manifest themselves in different ways in different parts of this network. Individual actors operate under no centrally orchestrated set of instructions or constraints. Where change occurs, it is because some sufficiently large body of individual actors see opportunity in undertaking the change or perceive unacceptable risk in not changing. The result for the Internet appears to be that some changes are very challenging, while others look like natural and inevitable progressive steps.
But the other side of the story is one that is about as diametrically opposed as its possible to paint. Over the last decade we’ve seen another profound revolution in the Internet as it embraced a combination of wireless-based infrastructure and a rich set of services at a speed which has been unprecedented. We’ve seen a revolution in content and content provision that has not only changed the Internet, but as collateral damage the Internet appears to be decimating the traditional newspaper and broadcast television sectors. Social media has all but replaced the social role of the telephone and the practice of letter writing. We’ve seen the rise of the resurgence of a novel twist to the old central mainframe service in the guise of the ‘cloud’ and the repurposing of Internet devices to support views of a common cloud-hosted content that in many ways mimic the function of display terminals of a bygone past. All of these are fundamental changes to the Internet and all of these have occurred in the last decade!
That’s a significant breadth of material to cover, so I’ll keep the story to the larger themes, and to structure this story, rather than offer a set of unordered observations about the various changes and developments over the past decade, I’ll use a standard model of a protocol stack as the guiding template. I’ll start with the underlying transmission media and then looking at IP, the transport layer, then applications and services, and closing with a look at the business of the Internet to highlight the last decade’s developments.
Below the IP Layer
What’s changed in network media?
Optical systems have undergone sustained change in the past decade. A little over a decade ago production optical systems used simple on-off keying to encode the signal into the optical channel. The speed increases in this generation of optical systems relied on improvements in the silicon control systems and the laser driver chips. The introduction of wavelength division multiplexing in the late 1990’s allowed the carriers to greatly increase the carrying capacity of their optical cable infrastructure. The last decade has seen the evolution of optical systems into areas of polarisation and phase modulation to effectively lift the number of bits of signal per baud. These days 100Gbps optical channels are commonly supportable, and we are looking at further refinements in signal detection to lift that beyond 200Gbps. We anticipate 400Gbps systems in the near future, using various combinations of a faster basic baud rate and higher levels of phase amplitude modulation, and dare to think that 1Tbps is now a distinct near term optical service.
Radio systems have seen a similar evolution in overall capacity. Basic improvements in signal processing, analogous to the changes in optical systems, has allowed the use of phase modulation to lift the data rate of the radio bearer. The use of MIMO technology, coupled with the use of higher carrier frequencies has allowed the mobile data service to support carriage services of up to 100Mbps in today’s 4G networks. The push to even higher frequencies promises speeds of up to 1Gbps for mobile systems in the near future with the deployment of 5G technology.
While optical speeds are increasing, ethernet packet framing still persists in transmission systems long after the original rationale for the packet format died along with that bright yellow coaxial cable! Oddly enough, the Ethernet-defined minimum and maximum packet sizes of 64 and 1500 octets still persist. The inevitable result of faster transmission speeds with constant packet sizes results in an upper bound of the number of packets per second increasing more 100-fold over the past decade, in line with the increase of deployed transmission speeds from 2.5Gbps to 400 Gbps. As a consequence, higher packet processing rates are being demanded from silicon-based switches. But one really important scaling factor has not changed for the past decade, namely the clock speed of processors and the cycle time of memory, which has not moved at all. The response so far has been in increasing reliance of parallelism in high speed digital switching applications, and these days multi-core processors and highly parallel memory systems are used to achieve performance that would be impossible in a single threaded processing model.
In 2018 it appears that we are close to achieving 1Tbps optical systems and up to 20Gbps in radio systems. Just how far and how quickly these transmission models can be pushed into supporting ever higher channel speeds is an open question.
The IP Layer
The most notable aspect of the network that appears to stubbornly resist all forms of pressure over the last decade, including some harsh realities of acute scarcity, is the observation that we are still running what is essentially an IPv4 Internet.
Over this past decade we have exhausted our pools of remaining IPv4 addresses, and in most parts of the world the IPv4 Internet is running on some form of empty. We had never suspected that the Internet would confront the exhaustion of one its most fundamental pillars, the basic function of uniquely addressing connected devices, and apparently shrug it off and continue on blithely. But, unexpectedly, that’s exactly what’s happened.
Today we estimate that some 3.4 billion people are regular users of the Internet, and there are some 20 billion devices connected to it. We have achieved this using some 3 billion unique IPv4 addresses. Nobody thought that we could achieve this astonishing feat, yet it has happened with almost no fanfare.
Back in the 1900’s we had thought that the prospect of address exhaustion would propel the Internet to use IPv6. This was the successor IP protocol that comes with a four-fold increase in the bit width of IP addresses. By increasing the IP address pool to some esoterically large number of unique addresses (340 undecillion addresses, or 3.4 x 1038) we would never have to confront network address exhaustion again. But this was not going to be an easy transition. There is no backward compatibility in this protocol transition, so everything has to change. Every device, every router and even every application needs to change to support IPv6. Rather than perform comprehensive protocol surgery on the Internet and change every part of the infrastructure to support IPv6, we changed the basic architecture of the Internet instead. Oddly enough, it looks like this was the cheaper option!
Through the almost ubiquitous deployment of Network Address Translators (NATs) at the edges of the network, we’ve transformed the network from a peer-to-peer network into a client/server network. In today’s client/server Internet clients can talk to servers, and servers can talk back to these connected clients, but that’s it. Clients cannot talk directly to other clients, and servers need to wait for the client to initiate a conversation in order to talk to a client. Clients ‘borrow’ an endpoint address when they are talking to a server and release this address for use by other clients when they are idle. After all, endpoint addresses are only useful to clients in order to talk to servers. The result is that we’ve managed to cram some 20 billion devices into an Internet that only has deployed just 3 billion public address slots. We’ve achieved this though embracing what could be described as time-sharing of IP addresses.
All well and good, but what about IPv6? Do we still need it? If so, then then are we going to complete this protracted transition? Ten years later the answer to these questions remain unclear. On the positive side, there is a lot more IPv6 around now than there was ten years ago. Service Providers are deploying much IPv6 today than was the case in 2008. When IPv6 is deployed within a Service Provider’s network we see an immediate uptake from these IPv6-equipped devices. In 2018 it appears that one fifth of the Internet’s users (that itself is now estimated to number around one half of the planet’s human population) are capable of using the Internet over IPv6, and most of this has happened in the past 10 years. However, on the negative side the question must be asked: What’s happening with IPv6 for the other four fifths of the Internet? Some ISPs have been heard to make the case that they would prefer to spend their finite operating budgets on other areas that improve their customers’ experience such as increasing network capacity, removing data caps, acquiring more on-net content. Such ISPs continue to see deployment of IPv6 as a deferable measure.
It seems that today we are still seeing a mixed picture for IPv6. Some service providers simply see no way around their particular predicament of IPv4 address scarcity and these providers see IPv6 as a necessary decision to further expand their network. Other providers are willing to defer the question to some undefined point in the future.
Routing
While we are looking at what’s largely unchanged over the past decade we need to mention the routing system. Despite dire predictions of the imminent scaling death of the Border Gateway Protocol (BGP) ten years ago, BGP has steadfastly continued to route the entire Internet. Yes, BGP is as insecure as ever, and yes, a continual stream of fat finger foul-ups and less common but more concerning malicious route hijacks continue to plague our routing system, but the routing technologies in use in 2008 are the same as we use in today’s Internet.
The size of the IPv4 routing table has tripled in the past ten years, growing from 250,000 entries in 2008 to slightly more than 750,000 entries today. The IPv6 routing story is more dramatic, growing from 1,100 entries to 52,000 entries. Yet BGP just quietly continues to work efficiently and effectively. Who would’ve thought that a protocol that was originally designed to cope with a few thousand routes announced by a few hundred networks could still function effectively across a routing space approaching a million routing entries and a hundred thousand networks!
In the same vein, we have not made any major change to the operation of our interior routing protocols. Larger networks still use either OPSF or ISIS depending on their circumstances, while smaller networks may opt for some distance vector protocol like RIPv2 or even EIGRP. The work in the IETF on more recent routing protocols LISP and BABEL seem lack any real traction with the Internet at large, and while they both have interesting properties in routing management, neither have a sufficient level of perceived benefit to overcome the considerable inertia of conventional network design and operation. Again, this looks like another instance where inertial mass is exerting its influence to resist change in the network.
Network Operations
Speaking of network operation, we are seeing some stirrings of change, but it appears to be a rather conservative area, and adoption of new network management tools and practices takes time.
The Internet converged on using the Simple Network Management Protocol (SNMP) a quarter of a century ago, and despite its security weaknesses, its inefficiency, its incredibly irritating use of ASN.1, and its use in sustaining some forms of DDOS attacks, it still enjoys widespread use. But SNMP is only a network monitoring protocol, not a network configuration protocol, as anyone who has attempted to use SNMP write operations can attest.
The more recent Netconf and YANG efforts are attempting to pull this area of configuration management into something a little more usable than expect scripts driving CLI interfaces on switches. At the same time, we are seeing orchestration tools such as Ansible, Chef, NAPALM and SALT enter the network operations space, permitting the orchestration of management tasks over thousands of individual components. These network operations management tools are welcome steps forward to improve the state of automated network management, but it’s still far short of a desirable endpoint.
In the same time period as we appear to have advanced the state of automated control systems to achieve the driverless autonomous car, the task of fully automated network management appears to have fallen way short of the desired endpoint. Surely it must be feasible to feed an adaptive autonomous control system with the network’s infrastructure and available resources, and allow the control system to monitor the network and modify the operating parameters of network components to continuously meet the network’s service level objectives? Where’s the driverless car for driving networks? Maybe the next ten years might get us there.
The Mobile Internet
Before we move up a layer in the Internet protocol model and look at the evolution of the end-to-end transport layer, we probably need to talk about the evolution of the devices that connect to the Internet.
For many years the Internet was the domain of the desktop personal computer, with laptop devices serving the needs to those with a desire for a more portable device. At the time the phone was still just a phone, and their early forays into the data world were unimpressive.
Apple’s iPhone, released in 2007, was a revolutionary device. Boasting a vibrant colour touch sensitive screen, just four keys, a fully functional operating system, with WiFi and cellular radio interfaces, and a capable processor and memory, it’s entry into the consumer market space was perhaps the major event of the decade. Apple’s early lead was rapidly emulated by Windows and Nokia with their own offerings. Google’s position was more as an active disruptor, using an open licensing framework for the Android platform and its associated application ecosystem to empower a collection of handset assemblers. Android is used by Samsung, LG, HTC, Huawei, Sony, and Google to name a few. These days almost 80% of the mobile platforms use Android, and some 17% use Apple’s iOS.
For the human Internet the mobile market is now the Internet-defining market in terms of revenue. There is little in terms of margin or opportunity in the wired network these days, and even the declining margins of these mobile data environments represent a vague glimmer of hope for the one dominant access provider industry.
Essentially, the public Internet is now a platform of apps on mobile devices.
End to End Transport Layer
It’s time to move up a level in the protocol stack and look at end-to-end transport protocols and changes that have occurred in the past decade.
End-to-end transport was the revolutionary aspect of the Internet, and the TCP protocol was at the heart of this change. Many other transport protocols require the lower levels of the network protocol stack to present a reliable stream interface to the transport protocol. It was up to the network to create this reliability, performing data integrity checks and data flow control, and repairing data loss within the network as it occurred. TCP dispensed with all of that, and simply assumed an unreliable datagram transport service from the network and pushed to the transport protocol the responsibility for data integrity and flow control.
In the world of TCP not much appears to have changed in the past decade. We’ve seen some further small refinements in the details of TCP’s controlled rate increase and rapid rate decrease, but nothing that shifts the basic behaviours this protocol. TCP tends to use packet loss as the signal of congestion and oscillates its flow rate between some lower rate and this loss-triggering rate.
Or at least that was the case until quite recently. The situation is poised to change, and change in a very fundamental way, with the debut of Google’s offerings of BBR and QUIC.
The Bottleneck Bounded Rate control algorithm, or BBR, is a variant of the TCP flow control protocol that operates in a very different mode from other TCP protocols. BBR attempts to maintain a flow rate that sits exactly at the delay bandwidth product of the end-to-end path between sender and receiver. In so doing, tries to avoid the accumulation of data buffering in the network (when the sending rate exceeds the path capacity), and also tries to avoid leaving idle time in the network (where the sending rate is less than the path capacity). The side effect is that BBR tries to avoid the collapse of network buffering when congestion-based loss occurs. BBR achieves significant efficiencies from both wired and wireless network transmission systems.
The second recent offering from Google also represents a significant shift in the way we use transport protocols. The QUIC protocol looks like a UDP protocol, and from the network’s perspective it is simply a UDP packet stream. But in this case looks are deceiving. The inner payload of these UDP packets contain a more conventional TCP flow control structure and a TCP stream payload. However, QUIC encrypts its UDP payload so the entire inner TCP control is completely hidden from the network. The ossification of the Internet’s transport is due in no small part to the intrusive role of network middleware that is used to discarding packets that it does not recognise. Approaches such as QUIC allow applications to break out of this regime and restore end-to-end flow management as an end-to-end function without any form of network middleware inspection or manipulation. I’d call this development as perhaps the most significant evolutionary step in transport protocols over the entire decade.
The Application Layer
Let’s keep on moving up the protocol stack and look at the Internet from the perspective of the applications and services that operate across the network.
Privacy and Encryption
As we noted in looking at developments in end-to-end transport protocols, encryption of the QUIC payload is not just to keep network middleware from meddling with the TCP control state, although it does achieve that very successfully. The encryption applies to the entire payload, and it points to another major development in the past decade. We are now wary of the extent to which various forms of network-based mechanisms are used to eavesdrop on users and services. The documents released by Edward Snowden in 2013 portrayed a very active US Government surveillance program that used widespread traffic interception sources to construct profiles of user behaviour and by inference profiles of individual users. In many ways this effort to assemble such profiles is not much different to what advertising-funded services such as Google and Facebook have been (more or less) openly doing for years, but perhaps the essential difference is that of knowledge and implied consent. In the advertisers’ case this information is intended to increase the profile accuracy and hence increase the value of the user to the potential advertiser. The motivations of government agencies are more open to various forms of interpretation, and not all such interpretations are benign.
One technical response to the implications of this leaked material has been an overt push to embrace end-to-end encryption in all parts of the network. The corollary has been an effort to allow robust encryption to be generally accessible to all, and not just a luxury feature available only to those who can afford to pay a premium. The Let’s Encrypt initiative has been incredibly successful in publishing X.509 domain name certificates that free of cost, and the result is that all network service operators, irrespective of their size or relative wealth, can afford to use encrypted sessions, in the form of TLS, for their web servers.
The push to hide user traffic from the network and network-based eavesdroppers extends far beyond QUIC and TLS session protocols. The Domain Name System is also a rich source of information about what users are doing, as well as being used in many places to enforce content restrictions. There have been recent moves to try and clean up the overly chatty nature of the DNS, using query name minimisation to prevent unnecessary data leaks, and the development of both DNS over TLS and DNS over HTTPS to secure the network path between a stub resolver and its recursive server. This is very much a work in progress effort at present, and it will take some time to see if the results of this work will be widely adopted in the DNS environment.
We are now operating our applications in an environment of heightened paranoia. Applications do not necessarily trust the platform on which they are running, and we are seeing efforts from the applications to hide their activity from the underlying platform. Applications do not trust the network, and we are seeing increased use of end-to-end encryption to hide their activity from network eaves droppers. The use of identity credentials within the encrypted session establishment also acts to limit the vulnerability of application clients to be misdirected to masquerading servers.
The Rise and Rise of Content
Moving further up the protocol stack to the environment of content and applications we have also seen some revolutionary changes over the past decade.
For a small period of time the Internet’s content and carriage activities existed in largely separate business domains, tied by mutual interdependence. The task of carriage was to carry users to content, which implied that carriage was essential to content. But at the same time a client/server Internet bereft of servers is useless, so content is essential to carriage. In a world of re-emerging corporate behemoths, such mutual interdependence is unsettling, both to the actors directly involved, and to the larger public interest.
The content industry is largely the more lucrative of these two and enjoys far less in the way of regulatory constraint. There is no concept of any universal service obligation, or even any effective form of price control in the services they offer. Many content service providers use internal cross funding that allows them to offer free services to the public, as in free email, free content hosting, free storage, and similar, and fund these services through a second, more occluded, transaction that essentially sells the user’s consumer profile to the highest bidding advertiser. All this happens outside of any significant regulatory constraint which has given the content services industry both considerable wealth and considerable commercial latitude.
It should be no surprise that this industry is now using its capability and capital to eliminate its former dependence on the carriage sector. We are now seeing the rapid rise of the content data network (CDN) model, where instead of an Internet carrying the user to a diverse set of content stores, the content stores are opening local content outlets right next to the user. As all forms of digital services move into CDN hostels, and as the CDN opens outlets that are positioned immediately adjacent to pools of economically valuable consumers, then where does that leave the traditional carriage role in the Internet? The outlook for the public carriage providers is not looking all that rosy given this increasing marginalisation of carriage in the larger content economy.
Within these CDNs we’ve also seen the rise of a new service model enter the Internet in the form of cloud services. Our computers are no longer self-contained systems with processing and compute resources but look more and more like a window that sees the data stored on a common server. Cloud services are very similar, where the local device is effectively a local cache of a larger backing store. In a world where users may have multiple devices this model makes persuasive sense, as the view to the common backing store is constant irrespective of which device is being used to access the data. These cloud services also make data sharing and collaborative work far easier to support. Rather than creating a set of copies of the original document and then attempt to stitch back all the individual edits into a single common whole, the cloud model shares a document by simply altering the document’s access permissions. There is only ever one copy of the document, and all edits and comments on the document are available to all.
The Evolution of Cyber Attacks
At the same time as we have seen announcements of ever increasing network capacity within the Internet we’ve seen a parallel set of announcements that note new records in the aggregate capacity of Denial of Service attacks. The current peak volume is an attack of some 1.7Tbps of malicious traffic.
Attacks are now commonplace. Many of them are brutally simple, relying on a tragically large pool of potential zombie devices that are readily subverted and co-opted to assist in attacks. The attacks are often simple forms of attack, such as UDP reflection attacks where a simple UDP query generates a large response. The source address of the query is forged to be the address of the intended attack victim, and not much more need be done. A small query stream can result in a massive attack. UDP protocols such as SNMP, NTP, the DNS and memcache have been used in the past and doubtless will be used again.
Why can’t we fix this? We’ve been trying for decades, and we just can’t seem to get ahead of the attacks. Advice to network operators to prevent the leakage of packets with forged source addresses, RFC 2827, was published in two decades ago in 1998. Yet massive UDP-based attacks with forged source addresses persist all the way through today. Aged computer systems with known vulnerabilities continued to be connected to the Internet and are readily transformed into attack bots.
The picture of attacks is also becoming more ominous. Previously attributed to ‘hackers’ it was quickly realised that a significant component of these hostile attacks had criminal motivations. The progression from criminal actors to state-based actors is also entirely predictable, and we are seeing an escalation of this cyber warfare arena with the investment in various forms of exploitation of vulnerabilities being seen as part of a set of desirable national capabilities.
It appears that a major problem here is that collectively we are unwilling to make any substantial investment in effective defence or deterrence. The systems that we use on the Internet are overly trusting to the point of irrational credulity. For example, the public key certification system used to secure web-based transactions is repeatedly demonstrated to be entirety untrustworthy, yet that’s all we trust. Personal data is continually breached and leaked, yet all we seem to want to do is increase the number and complexity of regulations rather than actually use better tools that would effectively protect users.
The larger picture of hostile attack is not getting any better. Indeed, it’s getting very much worse. If any enterprise has a business need to maintain a service that is always available for use, then any form of in-house provisioning is just not enough to be able to withstand attack. These days only a handful of platforms are able to offer resilient services, and even then it’s unclear whether they could withstand the most extreme of attacks. There is a constant background level of scanning and probing going on in the network, and any form of visible vulnerability is ruthlessly exploited. One could describe today’s Internet as a toxic wasteland, punctuated with the occasional heavily defended citadel. Those who can afford to locate their services within these citadels enjoy some level of respite from this constant profile of hostile attack, while all others are forced to try and conceal themselves from the worst of this toxic environment, while at the same time aware that they will be completely overwhelmed by any large scale attack.
It’s a sobering through that about one half of the world’s population are now part of this digital environment. A more sobering thought is that many of today’s control systems, such as power generation and distribution, water distribution, and road traffic control systems are exposed to the Internet. Perhaps even more of a worry is the increasing use of the Internet in automated systems that include various life support functions. The consequences of massive failure of these systems in the face of a sustained and damaging attack cannot be easily imagined.
The Internet of Billions of Tragically Stupid Things
What makes this scenario even more depressing is the portent of the so-called Internet of Things.
In those circles where Internet prognostications abound and policy makers flock to hear grand visions of the future, we often hear about the boundless future represented by this “Internet of Things. This phrase encompasses some decades of the computing industry’s transition from computers as esoteric pieces of engineering affordable only by nations, to mainframes, desktops, laptops, handhelds, and now wrist computers. Where next? In the vision of the Internet of Things we are going to expand the Internet beyond people and press on with using billions of these chattering devices in every aspect of our world.
What do we know about the “things” that are already connected to the Internet?
Some of them are not very good. In fact some of them are just plain stupid. And this stupidity is toxic, in that their sometime inadequate models of operation and security affects others in potentially malicious ways. Doubtless if such devices were constantly inspected and managed we might see evidence of aberrant behaviour and correct it. But these are unmanaged devices that are all but invisible. There are the controller for a web camera, the so-called “smart” thin in a smart television, or what controls anything from a washing machine to a goods locomotive. Nobody is looking after these devices.
When we think of an Internet of Things we think of a world of weather stations, web cams, “smart” cars, personal fitness monitors and similar. But what we tend to forget is that all of these devices are built upon layers of other people’s software that is assembled into a product at the cheapest possible price point. It may be disconcerting to realise that the web camera you just installed has a security model that can be summarised with the phrase: “no security at all”, and its actually offering a view of your house to the entire Internet. It may be slightly more disconcerting to realise that your electronic wallet is on a device that is using a massive compilation of open source software of largely unknown origin, with a security model that is not completely understood, but appears to be susceptible to be coerced into being a “yes, take all you want”.
It would be nice to think that we’ve stopped making mistakes in code, and from now on our software in our things will be perfect. But that’s hopelessly idealistic. It’s just not going to happen. Software will not be perfect. It will continue to have vulnerabilities. It would be nice to think that this Internet of Things is shaping up as a market where quality matters, and consumers will select a more expensive product even though its functional behaviour is identical to a cheaper product that has not been robustly tested for basic security flaws. But that too is hopelessly naive.
The Internet of Things will continue to be a market place where the compromises between price and quality will continue to push us on to the side of cheap rather than secure. What’s going to stop us from further polluting our environment with a huge and diverse collection of programmed unmanaged devices with inbuilt vulnerabilities that will be all too readily exploited? What can we do to make this world of these stupid cheap toxic things less stupid and less toxic? Workable answers to this question have not been found so far.
The Next Ten Years
The silicon industry is not going to shut down anytime soon. It will continue to produce chips with more gates, finer tracks and more stacked layers for some years to come. Our computers will become more capable in terms of the rage and complexity of the tasks that they will be able to undertake.
At the same time, we can expect more from our network. Higher capacity certainly, but also greater levels of customisation of the network to our individual needs.
However, I find it extremely challenging to be optimistic about security and trust in the Internet. We have made little progress in this areas over the last ten years and there is little reason to think that the picture will change in the next ten years. If we can’t fix it, then, sad as it sounds, perhaps we simply need to come to terms with an Internet jammed full of tragically stupid things.
However, beyond these broad-brush scenarios, it’s hard to predict where the Internet will head. Technology does not follow a pre-determined path. It’s driven by the vagaries of an enthusiastic consumer market place that is readily distracted by colourful bright shiny new objects, and easily bored by what we quickly regard as commonplace.
What can we expect from the Internet in the next ten years that can outdo a pocket-sized computer that can converse with me in a natural language? That can offer more than immersive 3D video in outstanding quality? That can bring the entire corpus of humanity’s written work into a searchable database that can answer any of our questions in mere fractions of a second?
Personally, I have no clue what to expect from the Internet. But whatever does manage to capture our collective attention I am pretty confident that it will be colourful, bright, shiny, and entirely unexpected!